



How do you continue to deliver amazing results with limited time and resources?
Writing quality content that educates and persuades is still a surefire way to achieve your traffic and conversion goals.
But the process is an arduous, manual job that doesn’t scale.
Fortunately, the latest advances in Natural Language Understanding and Generation offer some promising and exciting results.
For his SEJ eSummit session, Hamlet Batista discussed what is possible right now using practical examples (and code) that technical SEO professionals can follow and adapt for their business.
Here’s a recap of his presentation.

Autocomplete Suggestions
How many times have you encountered this?
Am I the only one who is sometimes scared by how specific and relevant Google doc and Gmail suggestions are?
You're writing a text and [this whole part can be suggested].
I mean, it's great. But it's scary. 🤪😱
— Kristina Azarenko 📈 (@azarchick) May 11, 2020
You start typing on Gmail and Google automatically completes the whole part and it’s super accurate.
You know, it’s really fascinating, but at the same time, it can be really scary.
You might already be using AI technology in your work without you even realizing it.
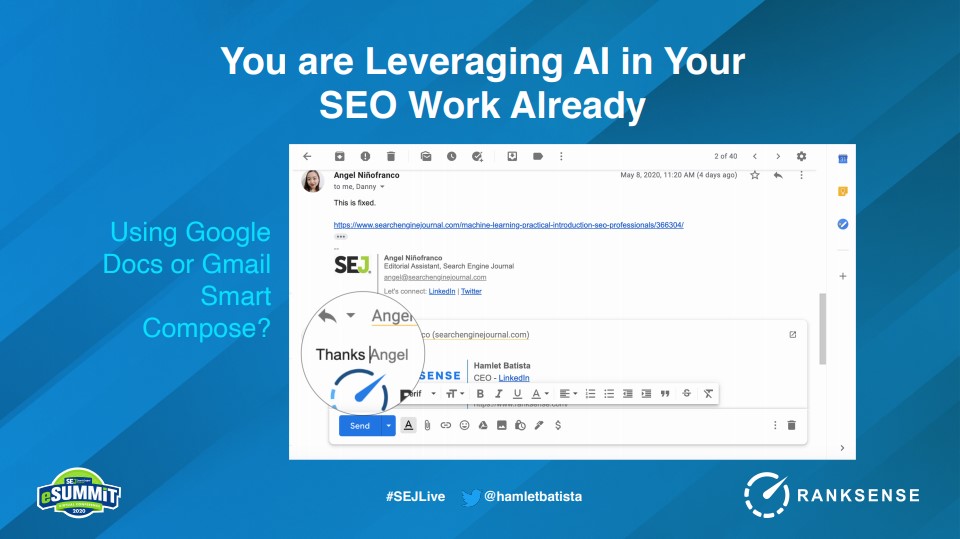
If you’re using Google Docs’ Smart compose feature, Gmail, or even Microsoft Word and Outlook, you’re already leveraging this technology.
This is part of your day as a marketer when you’re communicating with clients.
The great thing is this technology is not only accessible to Google.
Check out the Write With Transformer website, start typing, and hit the tab key for full sentence ideas.
Batista demonstrated how after plugging in the title and a sentence from a recent SEJ article, the machine can start generating lines – you just need to hit the autocomplete command.

All of the highlighted text above was completely generated by a computer.
The cool thing about this is that the technology that makes this possible is freely available and accessible to anybody who wants to use it.
Intent-Based Searches
One of the shifts we’re seeing right now in SEO is the transition to intent-based searches.
As Mindy Weinstein puts it in her Search Engine Journal article, How to Go Deeper with Keyword Research:
“We are in the era where intent-based searches are more important to us than pure volume.”
“You should take the extra step to learn the questions customers are asking and how they describe their problems.”
“Go from keywords to questions”
This change brings about an opportunity for us when we’re writing content.
The Opportunity
Search engines are answering engines these days.
And one effective way to write original, and popular content is to answer your target audience’s most important questions.
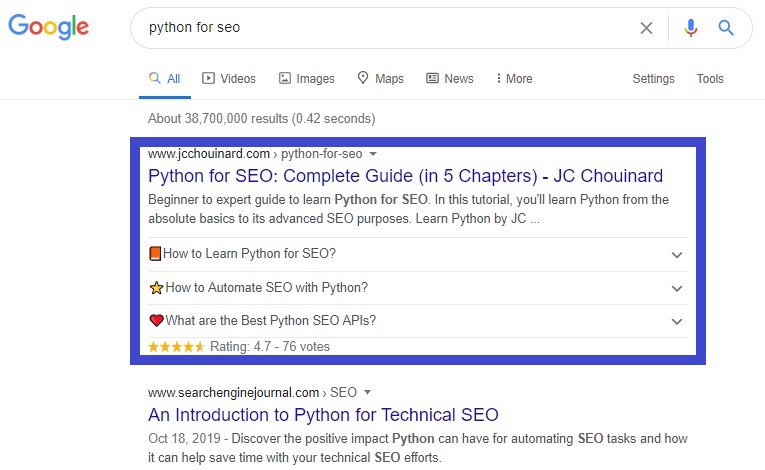
Take a look at this example for the query “python for seo”.
The first result shows we can leverage content that answers questions, in this case using FAQ schema.
FAQ search snippets take more real estate in the SERPs.
However, doing this manually for every piece of content you’re going to create can be expensive and time-consuming.
But what if we can automate it by leveraging AI and existing content assets?
Leveraging Existing Knowledge
Most established businesses already have valuable, proprietary knowledge bases that they have developed over time just by normal interactions with customers.
Many times these are not yet publicly available (support emails, chats, internal wikis).
Open Source AI + Proprietary Knowledge
Through a technique called “Transfer Learning”, we can produce original, quality content by combining proprietary knowledge bases and public deep learning models and datasets.
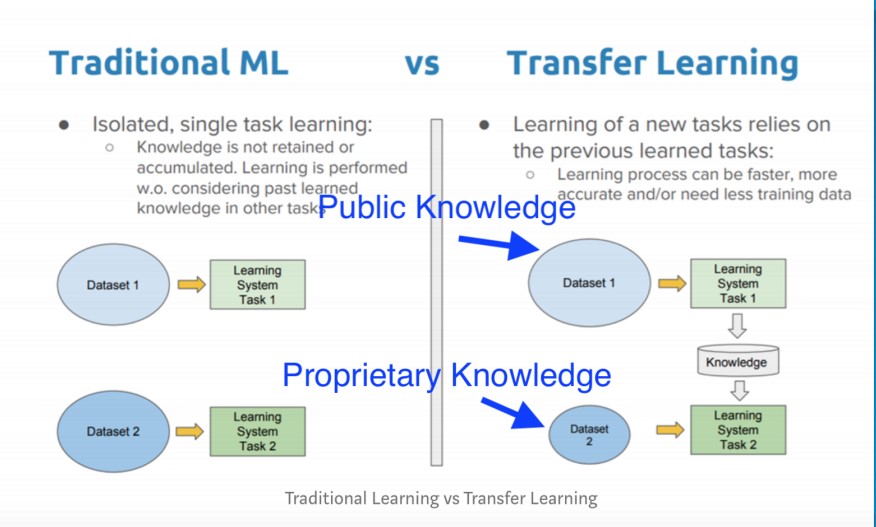
There are differences between traditional machine learning (ML) and deep learning, .
In traditional ML, you’re primarily doing classifications and leveraging existing knowledge to come up with the predictions.
Now with deep learning, you’re able to tap into common sense knowledge that has been built over time by big companies like Google, Facebook, Microsoft, and others.
During the session, Batista demonstrated how this can be done.
How to Automate Content Generation
Below are the steps to take when reviewing automated question and answer generation approaches.
- Source popular questions using online tools.
- Answer them using two NLG approaches:
- A span search approach.
- A “closed book” approach.
- Add FAQ schema and validate using the SDTT.
Sourcing Popular Questions
Finding popular questions based on your keywords is not a big challenge since there are free tools you can use to do this.
Answer the Public
Simply type a keyword and you can get plenty of questions that users are asking.

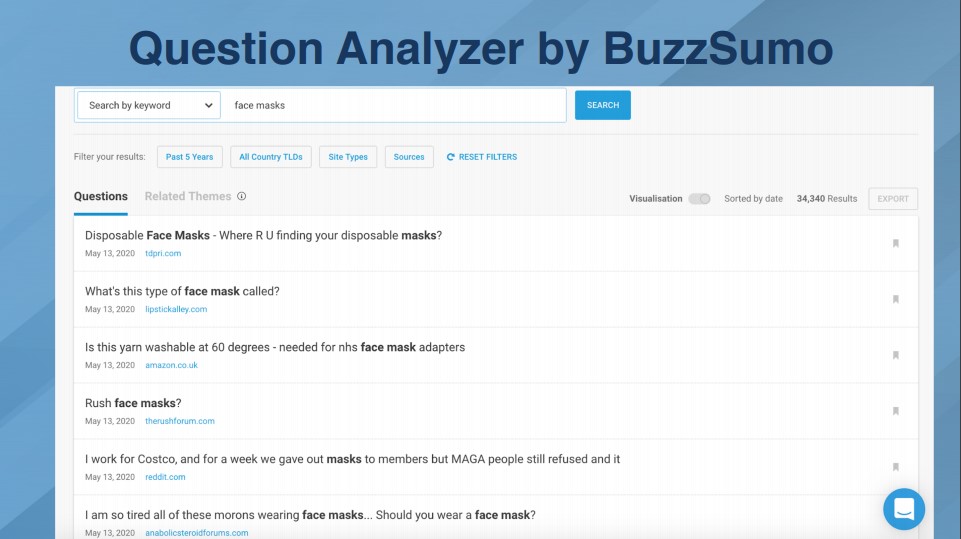
Question Analyzer by BuzzSumo
They aggregate information from forums and other places. You can also find more long-tail type of questions.
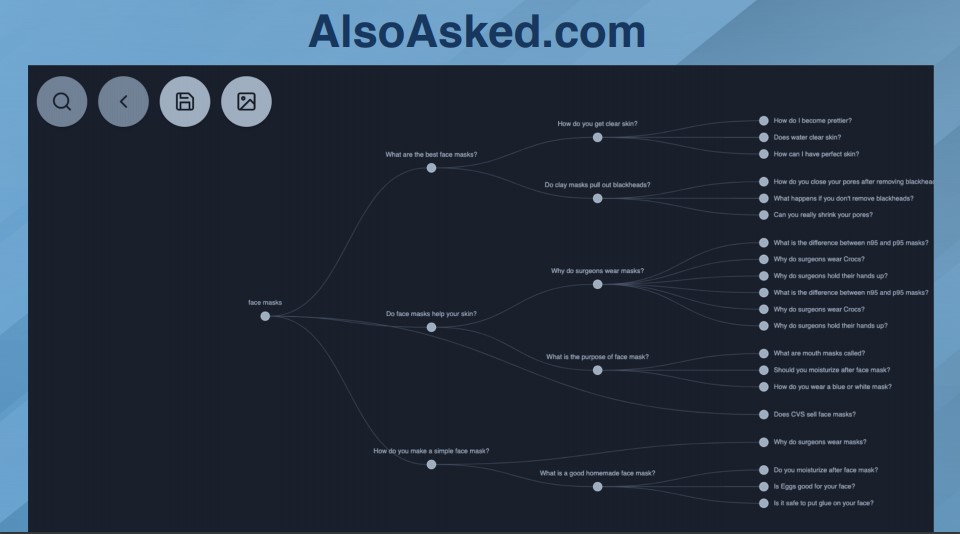
AlsoAsked.com
This tool scrapes the People Also Ask questions from Google.
Question & Answering System
The Algorithm
Papers With Codes is a great source of leading-edge research about Question Answering.
It allows you to freely tap into the latest research that is being published.
Academics and researchers post their research so they can get feedback from their peers.
They’re always challenging each other to come up with a better system.
What’s more interesting is that even people like us can access the code that we’re going to need to answer the questions.
For this task, we’re going to use T5, or Text-to-Text Transfer Transformer.
The Dataset
We also need the training data that the system is going to use to learn to answer questions.
The Stanford Question Answering Dataset 2.0 (SQuAD 2.0) is the most popular reading comprehension dataset.
Now that we have both the data set and the code, let’s talk about the two approaches we can use.
- Open-book question answering: You know where the answer is.
- Closed-book question answering: You don’t know where the answer is.
Approach #1: A Span Search Approach (Open Book)
With three simple lines of code, we can get the system to answer our questions.
This is something you can do in Google Colab.
Create a Colab notebook and type the following:
!pip install transformers
from transformers import pipeline# Allocate a pipeline for question-answering
nlp = pipeline('question-answering')nlp({
'question': 'What is the name of the repository ?',
'context': 'Pipeline have been included in the huggingface/transformers repository'
})
When you type the command – providing a question, as well as the context that you think has the answer to the question – you will see the system basically perform a search for the string that has the answer.
{'answer': 'huggingface/transformers',
'end': 59,
'score': 0.5135626548884602,
'start': 35}
The steps are simple:
- Load the Transformers NLP library.
- Allocate a Question Answering pipeline.
- Provide the question and context (content/text most likely to include the answer).
So how are you going to get the context?
With a few lines of code.
!pip install requests-html
from requests_html import HTMLSession
session = HTMLSession()
url = "https://www.searchenginejournal.com/uncover-powerful-data-stories-phyton/328471/"
selector = "#post-328471 > div:nth-child(2) > div > div > div.sej-article-content.gototop-pos"
with session.get(url) as r:
post = r.html.find(selector, first=True)
text = post.textUsing the request HTML library, you can pull the URL – which is equivalent to navigating the browser to the URL – and providing a selector (which is the path of the element of the block of text on the page.)
I should simply make a call to pull the content and add it to the text – and that becomes my context.
In this instance, we’re going to ask a question that is included in an SEJ article.
That means we know where the answer is. We’re providing the article that has the answer.
But what if we don’t know what article contains the answer then we’re trying to ask?
Approach #2: Exploring the Limits of NLG with T5 & Turing-NLG (Closed Book)
Google’s T5 (11-billion parameter model) and Microsoft’s TuringNG (17-billion parameter model) are able to answer questions without providing any context.
They are so massive that they’re able to keep a memory of a lot of things when they were training.
The Google’s T5 team went head-to-head with the 11-billion parameter model in a pub trivia challenge and lost.
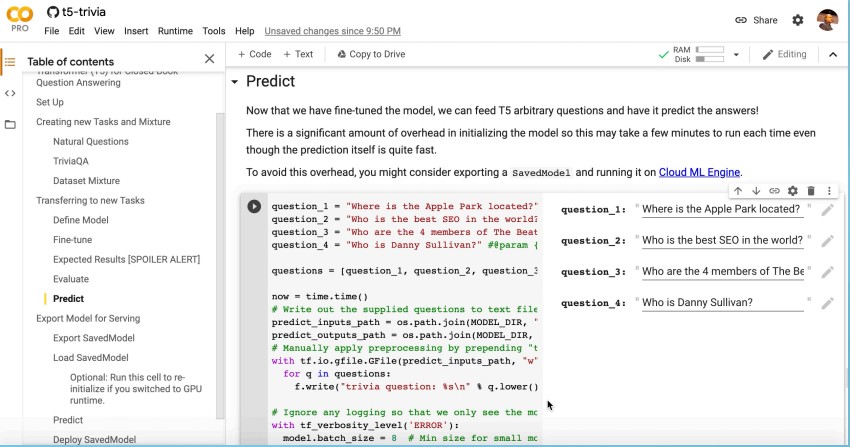
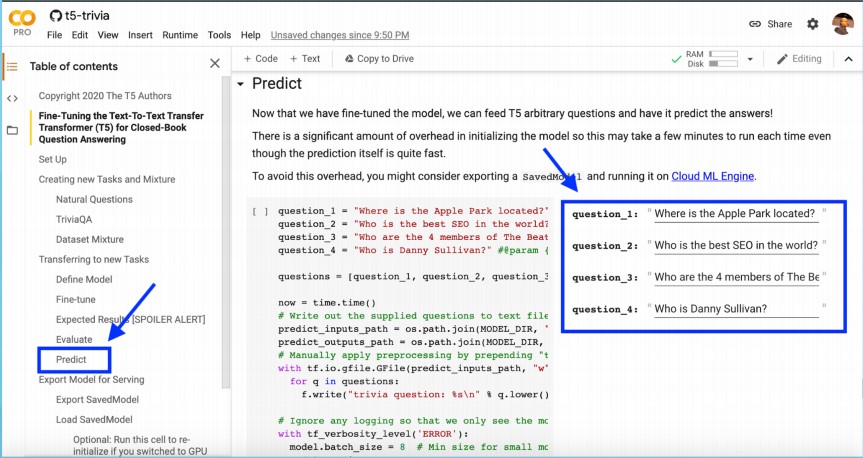
Let’s see how simple it is to train T5 to answer our own arbitrary questions.
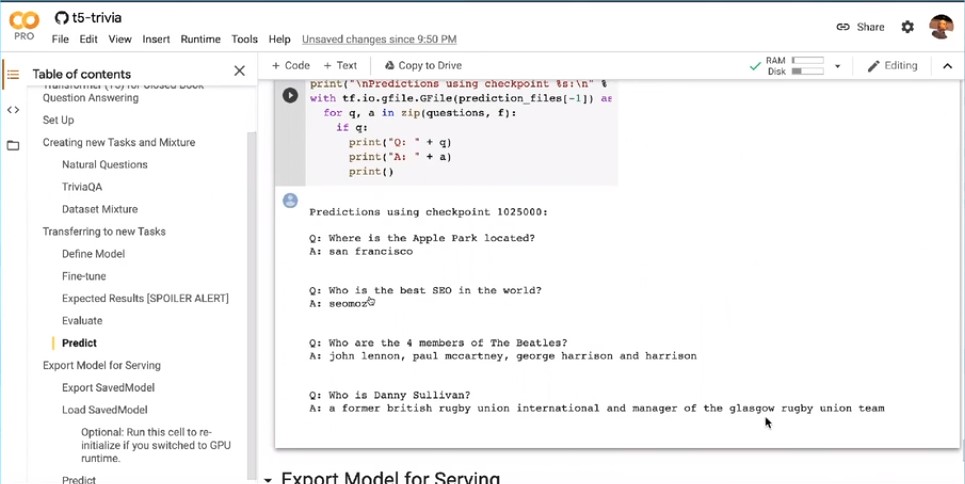
In this example, one of the questions Batista asked is “Who is the best SEO in the world?”
 T5 answering arbitrary questions.
T5 answering arbitrary questions.The best SEO in the world, according to a model that was trained, by Google is SEOmoz.
How to Train, Fine-Tune & Leverage T5
Training T5
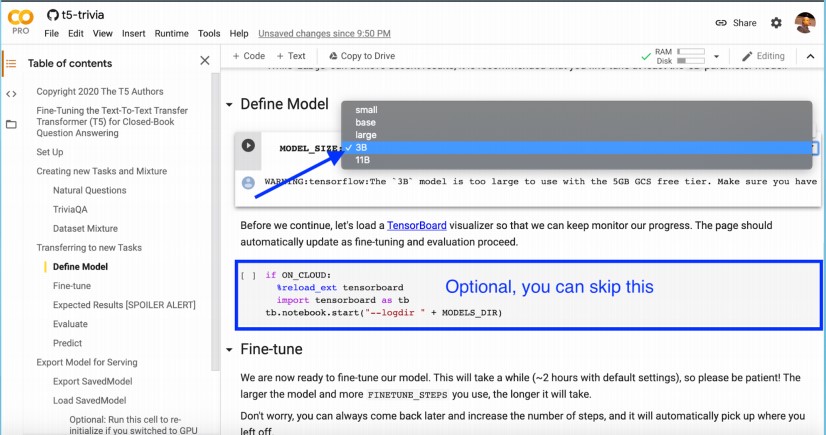
We are going to train the 3-billion parameter model using a free Google Colab TPU.
Here is the technical plan for using T5:
- Copy the example Colab notebook to your Google Drive.
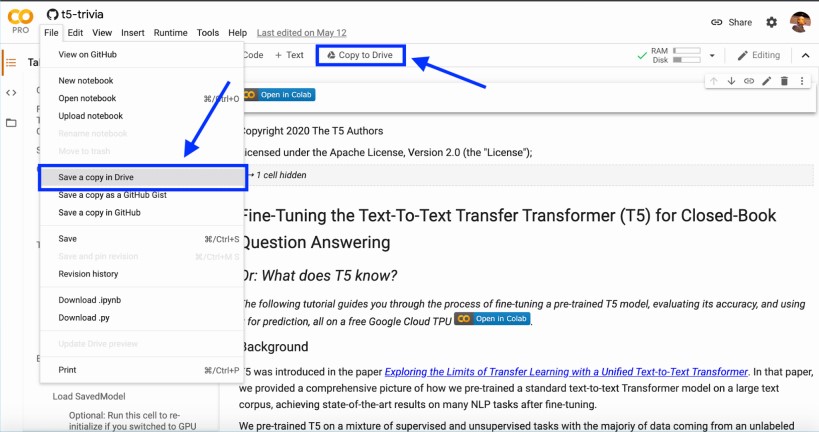
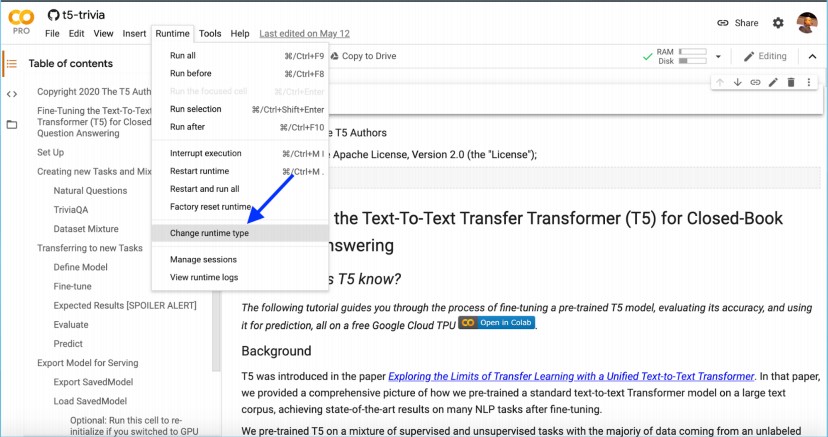
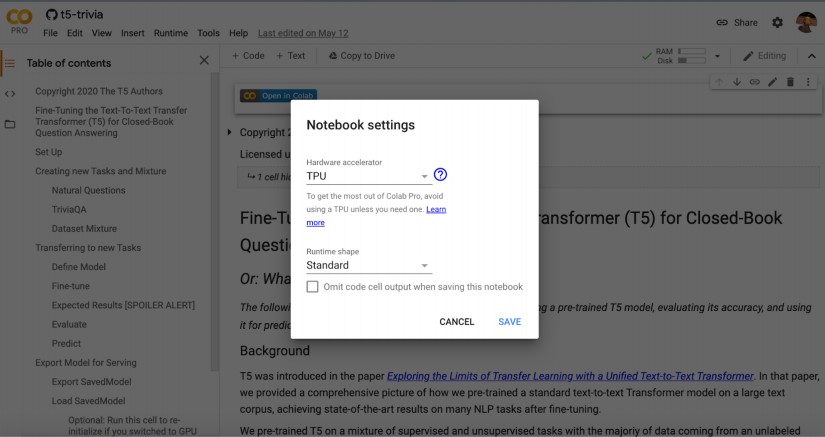
- Change the runtime environment to Cloud TPU.
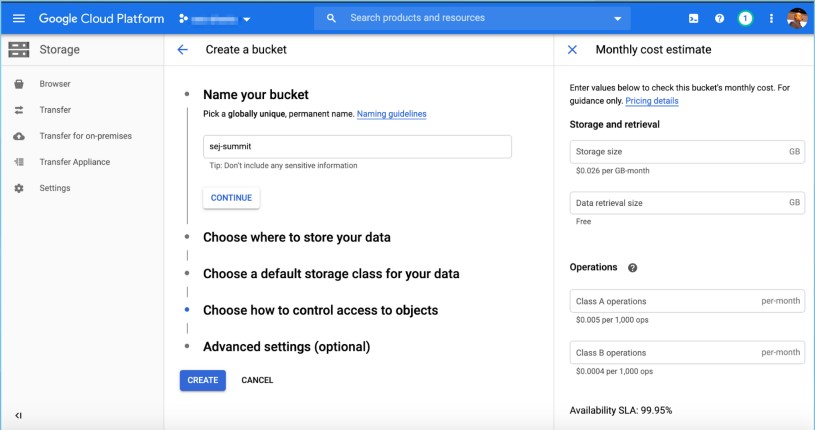
- Create a Google Cloud Storage bucket (use the free $300 in credits).
- Provide the bucket path to the notebook.
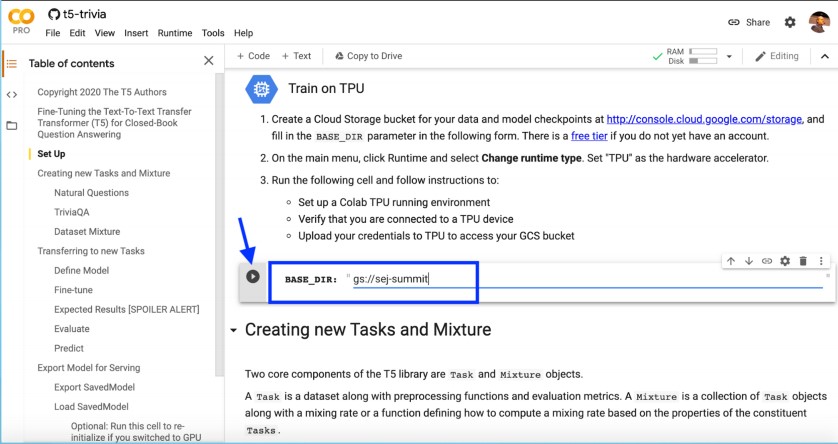
- Select the 3-billion parameters model.
- Run the remaining cells up to the prediction step.
And now you’ve got a model that can actually answer questions.
But how do we add your proprietary knowledge so that it can answer questions in your domain or industry from your website?
Adding New Proprietary Training Datasets
This is where we go into the fine-tuning step.
Just click on the Fine-tune option in the model.
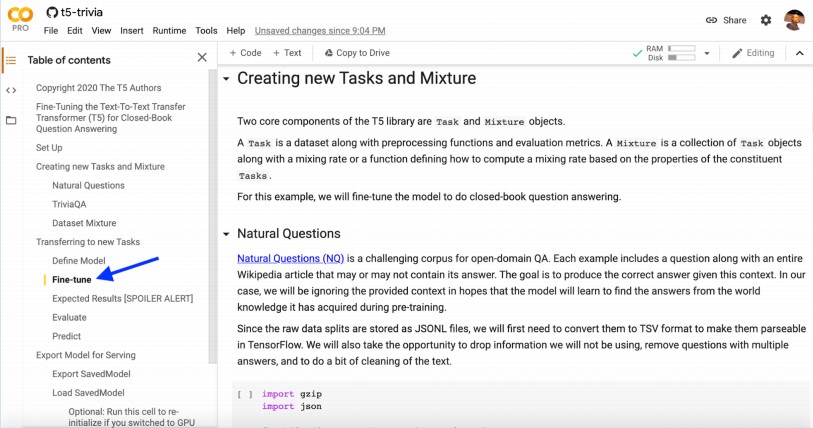
And there are some examples in the code of how to create new functionality and how to give new capabilities to the model.
Remember to:
- Preprocess your proprietary knowledge base into a format that can work with T5.
- Adapt the existing code for this purpose (Natural Questions, TriviaQA).
To learn the extract, transform, and load process for machine learning, read Batista’s Search Engine Journal article, A Practical Introduction to Machine Learning for SEO Professionals.
Adding FAQ Schema
This step is straight forward.
Simply go to the Google documentation for the FAQ: Mark up your FAQs with structured data.
Add the JSON-LD structure for that.
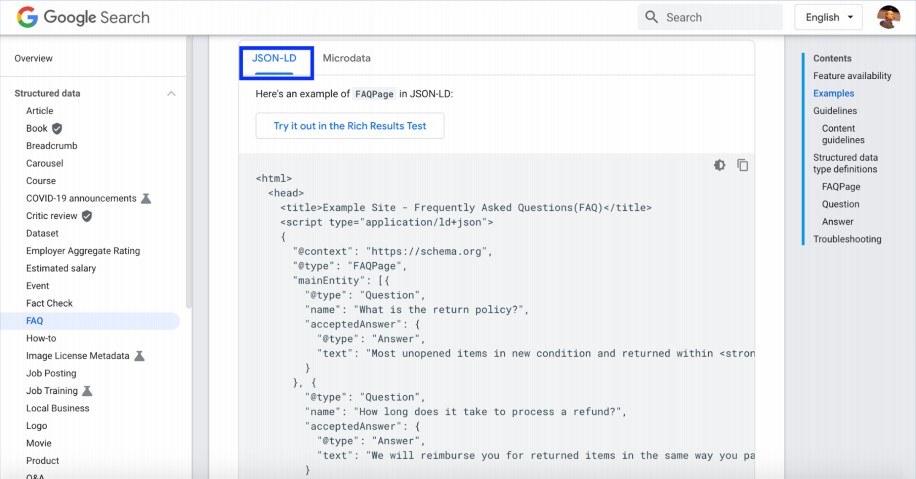
Do you want to do it automatically?
Batista also wrote an article about it: A Hands-On Introduction to Modern JavaScript for SEOs.
With JavaScript, you should be able to generate this JSON-LD.
Resources to Learn More:
- Introduction to Python for SEOs
- Introduction to Machine Learning for SEOs
- Leverage SOTA models with one line of code
- Exploring Transfer Learning with T5
- Deep Learning on Steroids with the Power of Knowledge Transfer
- MarketMuse First Draft
Watch this Presentation
You can now watch Batista’s full presentation from SEJ eSummit on June 2.
Image Credits
Featured Image: Paulo Bobita
All screenshots taken by author, July 2020
